为什么“壁垒”成了互联网公司的生死线?
流量红利见顶、获客成本飙升,没有壁垒的产品只能陷入价格战。投资人看项目时,第一个问题往往是:“如果腾讯/阿里/字节跟进,你怎么办?”答案若只是“我们更快”,基本就出局了。
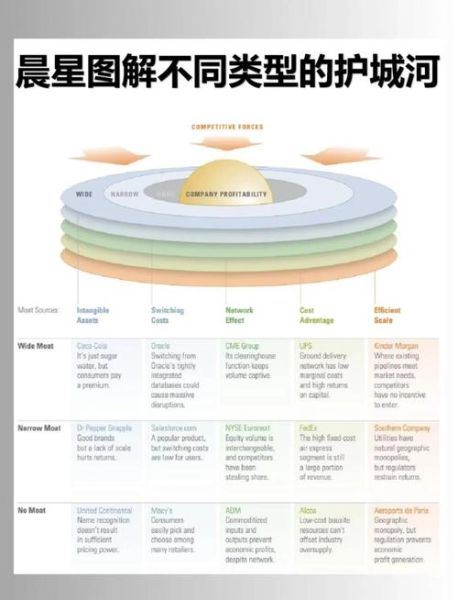
互联网壁垒的四大类型与落地方法
1. 技术壁垒:把算法炼成“黑盒”
自问:技术领先三个月算不算壁垒?
自答:算,但前提是你能持续迭代。OpenAI的GPT系列每半年升级一次,对手刚复现上一代,新版本又发布。落地动作:
- 申请算法专利+软件著作权双重保护
- 核心代码分层部署,前端开源、后端闭源
- 建立数据飞轮:用户越多→模型越准→体验越好→用户更多
2. 数据壁垒:让用户“自愿”贡献生产资料
自问:手里只有10万条数据,如何滚到千万级?
自答:把数据收集嵌入用户核心路径。例如Keep的健身课程,用户每完成一次训练,就为平台贡献了运动时长、心率曲线、完成率等结构化数据。关键动作:
- 设计数据即服务的场景(如Keep的个性化训练计划)
- 用隐私计算打消用户顾虑:联邦学习+差分隐私
- 定期发布行业白皮书,把数据变成话语权
3. 网络效应壁垒:让离开的人“社交破产”
自问:微信的护城河仅仅是用户多吗?
自答:不,是关系链密度。当你的同事、家人、物业、甚至孩子班主任都在微信时,迁移成本趋近无穷大。构建方法:
- 双边冷启动:先补贴供给端(如滴滴早期给司机补贴),再撬动需求端
- 跨边网络效应:B站UP主越多→观众越多→广告主越多→UP主收入越高
- 工具转社区:Notion从文档工具→团队知识库→UGC模板市场
4. 生态壁垒:让对手“舍不得”砸钱复制
自问:为什么阿里云不怕后来者降价?
自答:因为客户用了RDS+OSS+Quick BI的整套解决方案,迁移涉及数据迁移、代码重构、员工培训,省下的云费用抵不上切换成本。实操步骤:
- 从单点工具扩展到工作流(如飞书从IM→文档→OKR→人事)
- 开放API+SDK,让第三方成为“免费销售”
- 设立生态基金,投资上下游形成利益共同体
初创公司如何低成本验证壁垒有效性?
用“假竞品”测试用户粘性
在Product Hunt发布一个功能完全抄袭你的MVP,观察:
- 多少用户会主动举报?(说明品牌心智已形成)
- 多少用户会留言求邀请码?(说明网络效应在起作用)
- 多少用户会留下邮箱等待迁移?(说明数据资产难以割舍)
避坑指南:这些“伪壁垒”正在拖垮团队
伪技术壁垒:过度依赖开源框架
某AI客服公司基于LangChain做二次开发,拿到融资后才发现技术方案完全可复制,对手用更低成本做出同样效果。
伪数据壁垒:买来的数据集
医疗影像公司花百万购买医院数据,但缺乏持续更新机制,模型上线半年就因数据漂移失效。
伪网络效应:补贴出来的“僵尸网络”
某社交App用现金激励拉新,DAU一度冲到百万,但停止补贴后留存率跌至5%——用户只为赚钱而来。
---未来五年,壁垒的进化方向
AI原生壁垒:从“模型”到“场景智能体”
下一代壁垒不再是单一模型,而是能自主调用工具、改写代码、优化流程的智能体。例如AutoGPT可以自动分析用户行为→生成SQL→优化推荐策略,对手复制的不只是算法,而是整个“思考-执行-迭代”闭环。
合规壁垒:把监管变成护城河
欧盟《AI法案》要求高风险AI系统必须通过CE认证,提前两年布局合规的初创公司,反而能把跨国巨头挡在门外。

最后提醒:壁垒不是规划出来的,是用真实用户场景“磨”出来的。每周问自己三个问题——
- 本周用户产生的不可替代数据是什么?
- 有多少用户主动邀请同事使用产品?
- 如果服务器宕机2小时,用户会发邮件催修复还是默默卸载?
这三个答案的变化曲线,就是你壁垒的“体检报告”。
评论列表