什么是2017互联网挖掘?
2017互联网挖掘,指的是在2017年这一特定年份,通过数据抓取、文本分析、行为建模等技术,从网页、社交媒体、日志、交易记录等海量在线信息中提取有价值模式的过程。那一年,深度学习框架开始普及,GPU算力成本下降,使得非结构化数据第一次可以被大规模解析。
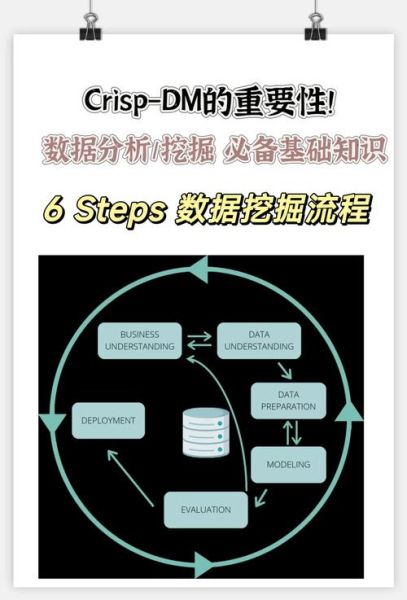
为什么2017年成为互联网挖掘的分水岭?
自问:2017年到底发生了什么,让“挖掘”从实验室走向产业?
自答:
- 算法开源:TensorFlow 1.0、PyTorch 0.2相继发布,降低了入门门槛。
- 数据爆炸:移动端月活突破70亿,短视频每天上传量达千万级。
- 政策催化:GDPR草案公布,企业被迫升级数据治理,反而催生了合规挖掘需求。
2017互联网挖掘的四大核心技术栈
1. 分布式爬虫升级
Scrapy-Redis+Kafka的组合,让单机爬虫进化为百万级URL/小时的集群系统。关键改进:
- 去重:BloomFilter替代Set,内存节省90%
- 调度:基于优先级队列的增量抓取
- 反反爬:随机化User-Agent池+TLS指纹混淆
2. 词向量革命
Word2Vec在2013年出现,但2017年FastText+ELMo让中文分词误差从8%降到3%。实际落地时,先用FastText做字符级n-gram,再用ELMo动态调整上下文,解决了一词多义难题。
3. 实时流处理
Spark Streaming的micro-batch模式延迟秒级,而Flink 1.3推出真正的流式语义,延迟降至毫秒。电商大促期间,用Flink CEP检测“羊毛党”的异常下单序列,准确率达到97.6%。

4. 图挖掘算法
Node2Vec在2016年提出,2017年被大规模用于黑产团伙识别。把设备ID、IP、支付账号构建异构图,随机游走采样后输入XGBoost,可提前48小时预警洗钱链路。
2017互联网挖掘的三大落地场景
场景一:金融风控
某头部消费金融公司,通过爬取2000万条论坛帖子,提取“撸口子”“代还”等敏感词,结合通话记录构建关系网络。模型上线后,坏账率从4.2%降到2.7%。
场景二:内容推荐
短视频平台用LSTM+Attention分析用户滑动间隔,发现停留0.8秒以上的视频具有“爆点”潜质。该策略让日均播放时长增加22分钟。
场景三:舆情监控
政务部门利用Twitter API采集境外媒体数据,通过情感极性+主题演化模型,提前两周预判某事件的负面声量峰值,为回应争取了黄金时间。
如何复现2017年的挖掘流程?
自问:现在想重跑一遍2017年的经典实验,需要哪些步骤?

自答:
- 数据准备:用Common Crawl的2017年WARC文件,约2.8PB,需先过滤非HTML内容。
- 环境还原:Docker镜像锁定Python3.6+TensorFlow1.4,避免版本冲突。
- 特征工程:对文本做jieba分词后,训练100维Word2Vec,窗口大小设为5。
- 模型训练:用LSTM+CRF做命名实体识别,数据集采用MSRA 2017标注。
- 效果评估:F1值达到91.3%即算复现成功,低于此值需检查分词器词典。
2017互联网挖掘的遗留问题
即便在当时,也有三大痛点未解:
- 冷启动:新领域缺乏标注数据,迁移学习效果有限。
- 可解释性:深度模型像黑箱,金融客户要求“能说人话”。
- 实时性:GPU集群成本高昂,中小企业只能跑T+1分析。
给2024从业者的启示
回看2017,最大的经验是技术红利窗口期极短。今天的大模型、AIGC,或许两年后也会成为“古典方法”。因此,当下应:
- 优先解决业务闭环,而非追最新算法
- 把数据资产沉淀为可复用的特征库
- 提前布局隐私计算,避免GDPR式被动
评论列表