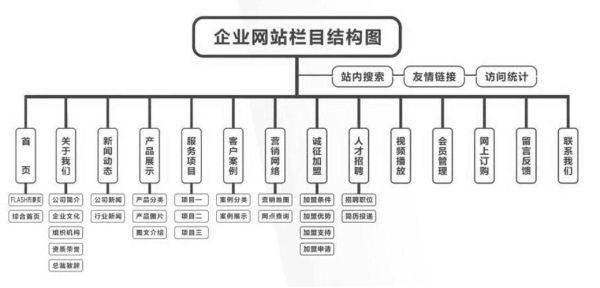
为什么网站结构是SEO成败的第一道门槛?
搜索引擎爬虫进入首页后,能否在三次点击内抓取到所有重要页面,直接决定索引量。**扁平化层级+清晰的URL规则**,能让权重快速传递,反之则造成大量孤岛页面。很多站长把精力放在外链,却忽略了内部路径的疏通,这是典型的本末倒置。

(图片来源网络,侵删)
如何用最少的层级覆盖最多的关键词?
1. 建立主题集群(Topic Cluster)
把核心词拆成若干子主题,每个子主题对应一个目录。例如“健身”拆成“家庭健身”“健身房攻略”“饮食计划”。目录名直接使用英文或拼音关键词,既方便爬虫识别,又减少动态参数。
2. 面包屑导航的隐藏价值
面包屑不仅提升用户体验,更在代码层面生成Schema.org结构化数据,让搜索结果出现层级路径,点击率可提升20%以上。务必保证每一级都可点击,避免使用JS生成。
URL静态化还是伪静态?哪个更利于收录?
百度官方明确表示不区分静态与伪静态,但参数越少、可读性越高的URL仍占优势。建议:
- 目录层级不超过三层
- 使用中划线“-”分隔单词,避免下划线
- 禁止出现“?id=123&sort=desc”这类动态符号
内链布局的“三不原则”
很多站点内链混乱,导致权重分散。遵循以下原则可解决:
- 不孤立:任何页面距离首页不超过三次点击
- 不重复:同一关键词指向不同URL不超过两次
- 不泛滥:正文内链占比控制在3%以内,避免被判定为作弊
移动端结构优化最容易踩的坑
自适应设计不等于移动友好。隐藏式菜单(汉堡按钮)会延迟重要链接的发现时间。解决方案:
(图片来源网络,侵删)
- 在移动端首页直接露出主导航的前三项
- 使用“推荐阅读”模块替代部分底部链接
- 对图片启用srcset属性,减少因加载延迟造成的抓取失败
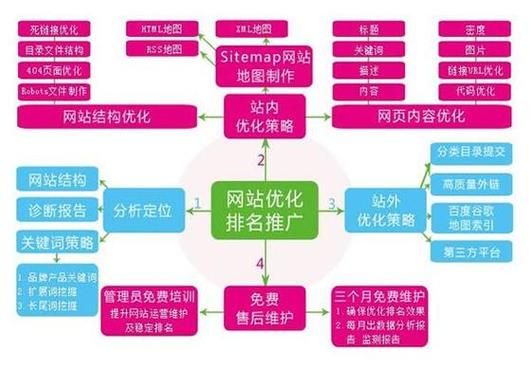
如何利用日志分析验证结构效果?
每周下载一次服务器日志,用Python或Shell脚本筛选百度蜘蛛记录,检查:
- 状态码非200的页面占比是否超过5%
- 抓取深度超过5层的URL列表
- 重复抓取但无变化的静态资源(如CSS/JS)
发现异常后,用robots.txt屏蔽无效路径,或通过sitemap提交更新。
大型站点必须掌握的自动化工具
人工维护上万级页面不现实,推荐组合:
- Screaming Frog:每周全站爬取,生成404、重定向链报告
- Ahrefs Batch Analysis:批量检查孤儿页面
- Python脚本:自动生成hreflang标签,解决多语言站点重复内容问题
网站改版时如何保住已有排名?
先在新环境完整测试,确认无误后按顺序执行:
- 全站301映射,一对一而非通配符,避免权重衰减
- 在Search Console提交改版规则,监控索引量波动
- 保留旧sitemap至少30天,引导爬虫更新缓存
未来趋势:语义化结构数据
随着MUM算法的普及,搜索引擎开始理解实体关系而非单纯关键词。在页面中嵌入JSON-LD格式的结构化数据,例如:
(图片来源网络,侵删)
{
"@context": "https://schema.org",
"@type": "HowTo",
"name": "如何优化网站结构",
"step": [
{"@type": "HowToStep", "text": "设计扁平化目录"},
{"@type": "HowToStep", "text": "部署面包屑导航"}
]
}此举可使页面获得富媒体摘要,抢占零点击流量。
评论列表