为什么医药市场数据分析越来越重要?
过去十年,全球医药市场规模从**1.1万亿美元**跃升至**1.6万亿美元**,年均复合增长率超过**5%**。在中国,这一数字更高达**9%**。面对政策、技术、需求三重变量,企业如果仍靠经验拍脑袋,失败概率会直线上升。通过系统化的市场数据分析,企业至少能把决策失误率降低**30%**。
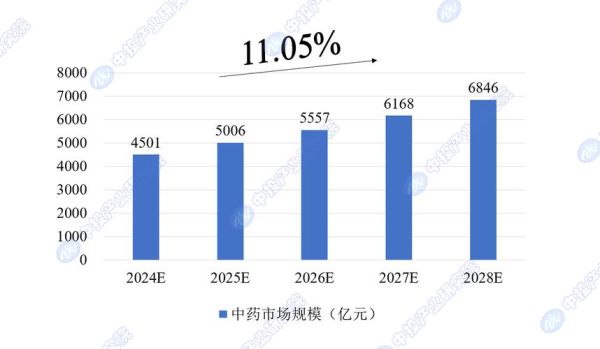
医药市场数据分析的核心维度有哪些?
1. 政策维度:带量采购与医保谈判的量化影响
带量采购已覆盖**370个品种**,平均降价**53%**。企业需要建立**价格弹性模型**:
- 测算中标后销量增幅能否抵消价格跌幅
- 评估未中标时渠道补位所需营销费用
- 监控竞品中标后的市场份额迁移速度
2. 技术维度:创新药与生物类似物的生命周期
以PD-1为例,国内上市**16个品种**后,价格从年费用**30万元**跌至**4万元**。关键指标:
- 专利悬崖前**3年**开始布局生物类似物
- 监测临床III期管线数量,**超过5家**即触发预警
- 追踪FDA突破性疗法认定名单,提前**18个月**锁定潜力靶点
3. 需求维度:老龄化与慢病管理的支付意愿
中国**60岁以上人口**已达**2.8亿**,糖尿病用药市场**年增速12%**。需重点关注:
- 医保支付比例与患者自付比例的临界点(通常为**70%:30%**)
- 基层医疗机构诊断率提升带来的增量市场(年增幅**8-10%**)
如何构建医药市场预测模型?
数据层:三类数据源的黄金组合
处方数据:覆盖**80%**三甲医院,滞后**45天**更新,用于监测竞品动态
零售终端数据:反映自费市场真实需求,尤其适合OTC与保健品
临床试验注册平台:提前**3-5年**预判竞争格局变化
算法层:从线性回归到机器学习
传统ARIMA模型在**政策突变**时误差可达**40%**,建议采用:
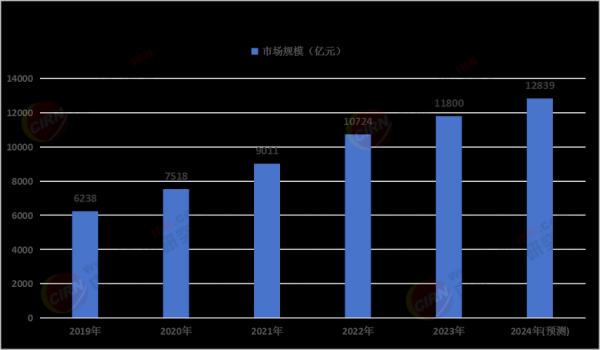
- LSTM神经网络处理带量采购的脉冲式影响
- 贝叶斯结构时间序列**(BSTS)量化医保目录调整的不确定性
- 用**SHAP值**解释模型,避免"黑箱"决策
验证层:动态回测机制
每季度用最新数据回测模型,设置**预警阈值**:
- 销量预测偏差**>15%**触发人工复核
- 价格预测偏差**>8%**启动竞品情报专项
实战案例:某生物药企如何预测阿达木单抗市场
背景:原研药修美乐专利**2023年到期**,国内已有**6家**生物类似物获批。
- 数据采集:整合PDB样本医院数据+药店零售数据+医保支付记录
- 模型构建:采用竞争扩散模型,设定生物类似物渗透率上限**65%**(参照欧洲经验)
- 情景模拟:
- 乐观:医保降价**40%**带动渗透率**50%**
- 中性:降价**60%**渗透率**35%**
- 悲观:价格战降价**80%**渗透率仅**25%**
- 决策输出:选择**中性情景**制定产能规划,提前锁定**30%**原料药供应商份额
结果:实际市场走势与中性情景偏差**7%**,企业市占率超预期**12%**。
未来三年医药数据分析的进化方向
实时数据流处理
通过医院HIS系统直连,将数据滞后从**45天**缩短至**72小时**,特别适用于:
- 监测新药上市后**前8周**的爆发曲线
- 捕捉带量采购执行首月的渠道窜货
患者旅程数字化
整合电子病历、可穿戴设备、医保结算数据,构建**患者级预测模型**:
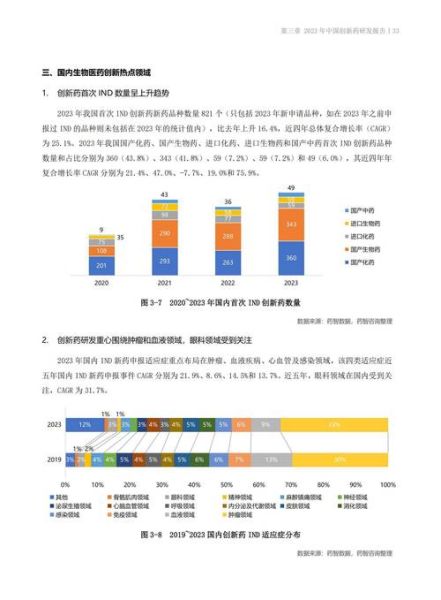
- 识别**30天内**可能停药的糖尿病患者
- 预测**6个月内**需要升级治疗方案的肿瘤患者
政策模拟器
基于历史医保谈判数据训练强化学习模型,可提前演练:
- 不同报价策略下的**谈判成功率**(误差<5%)
- 医保目录调整后**竞品替代路径**
企业落地数据分析的3个关键步骤
第一步:建立数据治理体系
- 设立**首席数据官**职位,直接向CEO汇报
- 制定**数据资产目录**,明确核心字段更新频率与责任人
第二步:培养复合型人才
- 医药背景+数据科学双技能团队占比需**>40%**
- 每年投入**营收的0.5%**用于员工数据分析培训
第三步:小步快跑验证价值
- 选择**1-2个核心产品**试点,设定**6个月**见效目标
- 用试点节省的**营销费用**反哺系统建设
当带量采购的降价幅度从**30%**演变为**90%**,当AI发现的靶点从**每年10个**暴增到**200个**,医药企业唯一能确定的,就是市场的不确定性本身。但正是这种不确定性,让数据分析从"锦上添花"变成了"生存必需"。
评论列表